Consistent hashing math
This is a derivation of the formulas that describe the distribution of work in systems using consistent hashing to share work. It is part technical paper, part demo and part blog post, so there is a lot of math, some web assembly, but also some jokes. My hope is that it will be complete and compelling but also approachable (and interesting?) for any reader regardless of background.
This is a companion piece to this blog post I wrote for Cloudflare, so check it out if you want to hear the complete story and how we used the math here to safely reclaim 100+ TB of RAM on the edge. It also has a basic primer on what consistent hashing even is.
Motivation
The main reason I'm writing this is to help out anyone in the future who is interested in this subject. When I first started researching the subject of consistent hashing and how its accuracy changes based on the number of hashes, I was frustrated by the resources that came up when googling. The results ranged from detailed (but utterly opaque to me) technical papers on the subject or understandable but incomplete derivations from online computer science class resources.
The payoff in both of these cases is an upper bound on the error in how evenly tasks are distributed with consistent hashing given in terms of asymptotic, "Big-O" limits
where is the number of hashes per server. It's not clear how closely the actual error matches that limit, so I set out to derive the actual formula and find out for myself. What I found was that all you need to solve this problem analytically is some high-school math and a little creativity.
TLDR
If you are here for a quick answer, I won't make you wait. The formula for consistent-hashing error for servers with hashes each is
Which is very close to if is large. In a system where the number of servers is 50 or more, the difference between the actual error value and the approximation is ~1%. It's a useful approximation, but without seeing what went into it, it's impossible to see what its other implications are. For instance, how do things change if each server has a different number of hashes? We will answer that question and more, so now let's prove it!
Part 1 - Single hashes
In order to get to the above equation, we need to start with a simpler entry point. When we use consistent hashing in practice, we operate on integers (normally 32 or 64-bit). This makes computations easier and faster as well as giving us access to well-behaved hash functions, but for our purposes it's going to be easier to consider hashes as real numbers between zero and 1 instead of a bounded range of integers.
Unfortunately, this does mean that the result I've already stated above is also an approximation (and thus I have already lied to you), but as you will see, this is a good approximation as long as your number of hashes and servers is not too big.
Baby Steps
Let's ease our way in and start with something small. Let's say we have a single server with a single hash that's part of a consistent hash setup with at least 1 more server. How do we determine the distribution for the workload that our server will handle? One easy way to think about this is geometrically. Recall from above that we are remapping the integer hash space to real numbers between 0 and 1; in this representation, the fraction of the work handled by our server is the same as the length of the segment assigned to it (Assuming the hashes of the tasks have a uniform distribution). Below is an interactive demo showing how the size of the region associated with our server can vary compared to the average size.
The error percentage shows how far off from the expected size our server's region is.
where is the total number of hashes.
After rerunning a few times you can see that the size of the region associated with our server varies wildly and that variation does not seem to depend on the total number of hashes. We'll see why that is in a moment.
Loop unrolling
One important thing to notice that I've glossed over so far is that the region between the first and last hash is connected making the hash domain effectively a ✨circle✨. That's why most posts about consistent hashing feature a graphic like the one below showing the angular ranges assigned to each server as a different color.
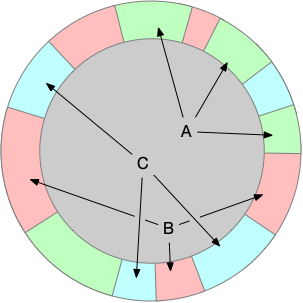
Looking at the ranges like this reinforces a fact we have already used. The absolute positions for the hashes for the servers do not matter. It's only their positions relative to each other that affect the distribution. In other words, there are no "special" points in the hash output, so we can choose our "zero" point to be anywhere. Setting zero to be equal to one of the hashes has the nice property that we no longer have to consider circular aspect of the hash ring.
Naturally the best point to choose to be our "zero" for simplicity is the hash associated with our server.
This reorientation of the hash space means that the length of the segment associated with our server is only determined by the minimum of all other hashes.
This is something we can calculate a statistical distribution for.
A little statistics
Statistics was the only class in college that I got a C in (Maybe I would have gone to class if it wasn't at 8am), so I don't feel like I have any right to lecture anyone on it ... but I'm going to anyway.
Ultimately we would like to be able to get the mean and standard deviation for the length of the segment associated with our server, and those are defined in terms of the probability-density function (PDF) for the length of the first segment. In order to get to the PDF we will start by first deriving its cumulative-distribution function (CDF).
Consider a point somewhere on our number line from 0 to 1. The CDF for the length of our segment is the probability that the length is . That probability is the same as the probability that the length is not which is
This is true because and are "complementary events" which is just a fancy way of saying that one or the other is always true, but never both. We make this change because is the the same as probability that all the hashes are . Since each hash is independent (meaning the value of one hash doesn't affect any other), we can say this probability of all being true is the product of the probability of each being independently true.
Determining the probability that an individual hash is is simply . We could prove this by integrating the PDF of the uniform distribution, but that's a bit boring (and we'll end up doing that later). Instead, here is another interactive demo that calculates the probability empirically via simulation.
So now that we know and we know that that probability is the same for every hash, we can put everything together to get the CDF for the length of our segment .
A little calculus 😅
Getting from CDF to PDF is a matter of differentiating the CDF by . So buckle up, this is where the calculus starts. Here we just need to use the distributive property and the power rule.
Which if we plot, looks like this.
Reality vs probability
Let's pause for a second before we use the PDF above to calculate the expected value and standard deviation to bring things back to reality. As you might have noticed, the PDF has values above 1. This should be a good clue that the PDF does not give you a way to look up the probability of a specific value ... so then like what good is it? ... and how do you find out the probability of a specific value?
The answer to both of those questions is histograms. As an answer to a purely mathematical problem it's maybe a little unsatisfying. Histogram are exceedingly practical tools that we typically use when measuring or visualizing things in the real world like latency or dB levels. The reason they come up here is because of the simplification we made at the very beginning. Our CDF and PDF above are based on the continuous range between 0 and 1 instead of the discrete length that will actually appear in our hash output. That simplification means that each specific length has infinite precision and therefor an infinitesimal probability by its self. In order to get an appreciable/useful value for probability, we have to look at the probability within a specific range of lengths. Plotting the probability between a bunch of different ranges is essentially the definition of a histogram, and the way we calculate the probability in that range is with the PDF (or CDF).
Using that definition we can create a new plot based on the derived PDF that shows the probability of a single-segment length with a variable histogram resolution.
Notice the plot still follows the same shape as the pdf. This makes sense since the expression is just a scaled approximation of the PDF at . Calculating the probability of our single segment having a value within a discrete range has the advantage that we can now compare our calculated distribution to some real-world simulated results. Is this necessary? No ... math is math ... but sometimes its helpful to prove to yourself that your math is the right math.
Below is an interactive demo that allows you to simulate a bunch of single-segment lengths and compare the empirical distribution with the derived one for a given number of hashes.
Excellent! After playing around with the possible values in the experiment above, it should be possible to convince yourself that our math does in fact math. Let's finish off this section by calculating the mean and standard deviation for the single-hash setup.
Single-hash distribution finale
We'll make this quick since we still have a long way to go. To get the expected value and standard deviation for the single-hash distribution, we can apply the definitions directly based on the PDF we derived above.
The expected value for the length of a single hash segment when there are total hashes is:
We can use integration by parts to evaluate this, so define and to be
Now with a little algebra and calculus autopilot we get the expected value in terms of .
Which is ... a little underwhelming given the amount of manipulation it took to get there, but it does at least make sense. The expected value is what you get when the whole hash space is split up evenly between all segments.
Let's move on the standard deviation calculation which is just the square root of the variance,
So we are actually going to calculate and save ourselves some radicals. Variance is defined as
We are going to do integration by parts again, but because our term has an in it, we will have to integrate by parts twice.
Now we can let the autopilot run again and find the variance for the length of single segment out of total hashes.
Now we can take the square root and get to the standard deviation.
It's worth pausing here at the end to think about what that standard deviation says in practical terms. Remember that (even if we've strayed into the abstract world a bit) this distribution is about how evenly we are sharing work between servers in the physical world. Standard deviation tells us the distance from the mean for most of the values in our distribution. In a sense it's a prediction of how much more or less load a server will handle than expected.
The drawback for standard deviation is that it's defined in absolute terms. You can see from the formula that the standard deviation goes down as the inverse to the total number of hashes. It would be easy to think that you could make a single-hash consistent hashing system more accurate by adding more total hashes, but that is forgetting that the portion of the range covered by a single segment also decreases as the inverse of the total number of hashes. So at the standard deviation is about , the expected size of the segment is , so the size of error on either side of the expected value is almost equal to the expected size.
A more useful analog for error in our consistent hashing systems (and the one I have been using until now without explanation) is coefficient of variation. CV is simply the standard deviation divided by the expected value or more simply, it's the error margin transformed to match the scale of what we expect. In our case the CV is
Which for our example gives a much more meaningful error of , and allows us to put a finger on just how bad single-hash consistent hashing is. For almost all values of H, the error rate is constant, and about 100%!
Luckily this single-segment derivation was only the tutorial boss for consistent hashing. Seeing how (and how much) we can improve consistent hashing is what we'll work on in the next section.
Interlude - Making hashes solvable
Deriving the distribution for consistent hashing scenarios with more than one hash per server on its face seems like a complicated and labor intensive problem. I think this is the main reason the articles I found on the subject make appeals to Chebyshev's inequality to establish an upper bound.
Looking at the literature that's out there (at least what's easy to find by googling) makes it seem like this problem is too difficult to be worth solving directly. Luckily for us, the analytical solution to the multi-segment case is not much more difficult than the single-segment case as long as you are willing to get onboard (with a sketch of a proof) a major simplification, and like I said before, it only takes some high-school level math (by which I mean calculus and statistics).
What exactly are we doing here?
Recall that in order to determine the percentage of work our server will handle in the single-segment case, we need to find the fraction of the hash output space assigned to our server. When we scaled our output space to fit between zero and one (and pretending it was continuous), all we needed to find was the length of the segment associated with our server. The only thing that changes in the multi-hash case is we need to find the probability distribution for the sum of the length of all the segments associated with our server.
Now we can shift our hashes around just like we did before so that the "zero" point falls on one of our servers hashes ... but it's not obvious which hash we should pick, nor is it obvious if that even buys us anything. Even with one hash nestled at the start of the number line, we still have a bunch of messy gaps to deal with. Getting rid of that messiness is going to require taking a step into the unknown. This is going to feel like that one weird trick to calculate your consistent hashing distribution, and I'll admit it doesn't seem like it should be legal. To help get you onboard, we'll condense the essence of our weird trick into one small step so that hopefully the subsequent steps feel logical (if not obvious).
Marbles and wires
What if we have just 2 hashes associated with our server? We can choose one of them to be the zero of our number line. The "zero" hash creates a segment that sits nicely at the beginning of the number line, but it leaves one more floating around out there creating a second segment at some random position index with some random size .
It's tempting to think that we could use the same formula above that we slogged through to describe the distribution for this second segment, and in a way we can. The formula we have is for the distribution for any single segment, so if we were looking our second segment alone without any other information, its length would follow the same distribution we found in the single segment case. Unfortunately if we're considering it by itself, it isn't really "second" anymore.
Considering the both segments at the same time leads us into the world of conditional probability. It exists to cover the gray area between when you know more than nothing and less than everything about a system. The classic example is removing colored marbles from a bag containing an equal number of red and green marbles. The first marble chosen has an equal chance of being red, but its removal means the second marble is less likely to have the same color as the first simply because there is 1 fewer of that color to choose from.
In general, the relationship between dependent random events (call them and ) is characterized by this equation:
We can see an analog in our 2-segment case in how the length of segment 1 affects the possibilities for the second. If segment 1 is really big, it leaves less room for the rest of the segments to occupy, so the second will be more likely to be smaller. Similarly if segment 1 is really small, the distribution for the second will approach what it would be if segment 1 wasn't even there. There is an important difference with the 2-segment distribution that we can exploit to make our math easier. The randomness in the marble scenario is in which marble is drawn. The randomness in our hash segment case is about the random length of a specific segment. We could think of the segments as being formed from taking a single wire and cutting it into parts, but we aren't really interested in pulling random wires out of a bag (or a drawer).

It's more like we have numbered bags, and each bag has a single wire of a random length where the total length is known. What's important here that there are no "special" bags. We can exchange any one bag for another, so the probability distribution for the length of the segment in each unopened bag must be the same!
Avoid empty space
If you'll recall that in the beginning of the previous section we were trying find the sum of the lengths of two segments. One on the far left of the number line with length and one at a random index with length . In terms of our wires in bags, we can find the sum of and with a 2-step process
- Take the wire from bag 1
- Add segment 1 to the segment in bag
We know from our discussion above that the length of the wire in bag 1 will be distributed like , and that knowing the length of will affect the distribution of (even if we don't know exactly how). But we also know there is nothing special about bag , so the distribution of all the other bags is changed in the same way meaning we could have chosen from any wire from any bag and the resulting distribution would be the same. So how about bag 2? Let's jump back to our original setup and apply what we just learned. Choosing bags 1 and 2 is the equivalent to measuring the 2 left-most segments in our number line.
This simplifies things considerably because we no longer have a random amount of space in between to account for. We can take this a step further by realizing that this "no special bags" trick works for any number of segments. The distribution for the sum of any segments is the same as the distribution for the first consecutive segments.
Part 2 - More than a single hash
Depending on your perspective, this is where things either get really interesting or this will feel like déjà vu. Thanks to some logic and (somehow) legit probability shell game, we now know the shape of the problem we need to solve to determine the consistent hashing error for a server with hashes out of a total of . What is the distribution for sum of the first segments on the number line? We already solved this with by cleverly defining a CDF using a little calculus to get from there to a PDF, variance and then finally to the error. Let's forget about being DRY and repeat ourselves.
Multi-hash CDF
Recall the definition for a CDF is that it tells us that probability that the thing we are looking for is smaller than a value . We'll denote our CDF for hashes as
But in order to write and expression for it, we'll need to do some leg work. Also notice we're bringing "sigma" notation, so now you know things are getting serious.
Recall that we used "complementary" events to write the CDF for the single-hash case. That was the how we were able to put the probability that the length of the first segment is less than framed in terms of the probability that all hashes are greater than . This reframing of the problem was important because it put a limit on the location of individual hashes, and each hash has a known uniform and independent distribution. That same complementary event trick works here, but not quite as cleanly. The complementary event for the sum of the first segments is simply that sum of the first segments is > .
That admittedly doesn't seem like a big step forward, but stay with me. Recall that we can pin the first hash at zero, so we can simplify the expression for the sum of the first hash segments to just the position of the -th smallest hash:
We can use this to rewrite the CDF for the sum of k segments as
While this insight doesn't give use a directly useable set of independent probabilities, it does allow us to simplify our length measuring problem in one of counting. Because if the -th smallest hash is , then it means the total number of hashes less than must be less than . Since we have pinned at 0, we can go a little further and say the the number of unpinned hashes (the only hashes that actually matter in our distribution) must be less than .
Let's introduce some new notation for this idea of counting the number of hashes that are . For a set of random hashes, we'll let be the count of hashes that are . Or if we want we wanted to be cool, we could write this as
But, in practical terms we can just think of as being like the sql count function. We can rewrite our CDF (yes, again) in terms of
This is a HUGE step forward because unlike or the values of , and the values of are integers. If we consider the specific case where , and we want to know the probability that the count of hashes no greater than is less than , we can literally check all possible values for a count less than and add them up!
Summing is safe here because there's no intersection between the events (the count can't be 1 and 2 at the same time). In general terms we can rewrite our CDF as.
Okay, so we have successfully kicked the can multiple steps down the road. The last step is to find a real formula for , and for that we're going to need to call up our good friend, Bernoulli.
Trials and choices
Bernoulli is a big name in mathematics and physics, but that's at least partially because there are two Bernoullis. Johann and Jacob were brothers and the sons of an apothecary. In addition to saddling them with a cutesy naming scheme, their father was a bit pushy. He pushed one towards a practical career in the spice trade, and the other into a respectable life as a theologian. Somehow they both ended up as famous mathematicians with works heavily geared towards gambling strategies. Jacob (for some reason 😉) wanted to know the "expected winnings for various games of chance" particularly in those with allowing multiple independent rounds and uniform odds of winning. The term Bernoulli trial comes directly from this work (albeit hundreds of years after it was published).
Cool story, bro, but how does this help us with consistent hashing?
So while the Bernoullis' motivations may not have been purely academic, the concept of Bernoulli trials is directly applicable to any situation with repeated tests where the outcomes are binary (yes/no) and the probability of yes is always the same. This could be a series of coin flips, dice rolls, or even 3-point shots (for a very consistent player). We can construct our own trial based on individual hash values. We'll consider a hash a "winner" if it less than .